
PERSPEKTIF GLOBAL TREN DAN PERKEMBANGAN INOVASI PENELITIAN VIDEO TO MUSIC GENERATION
DOI:
https://doi.org/10.31949/infotech.v11i1.13830Abstract
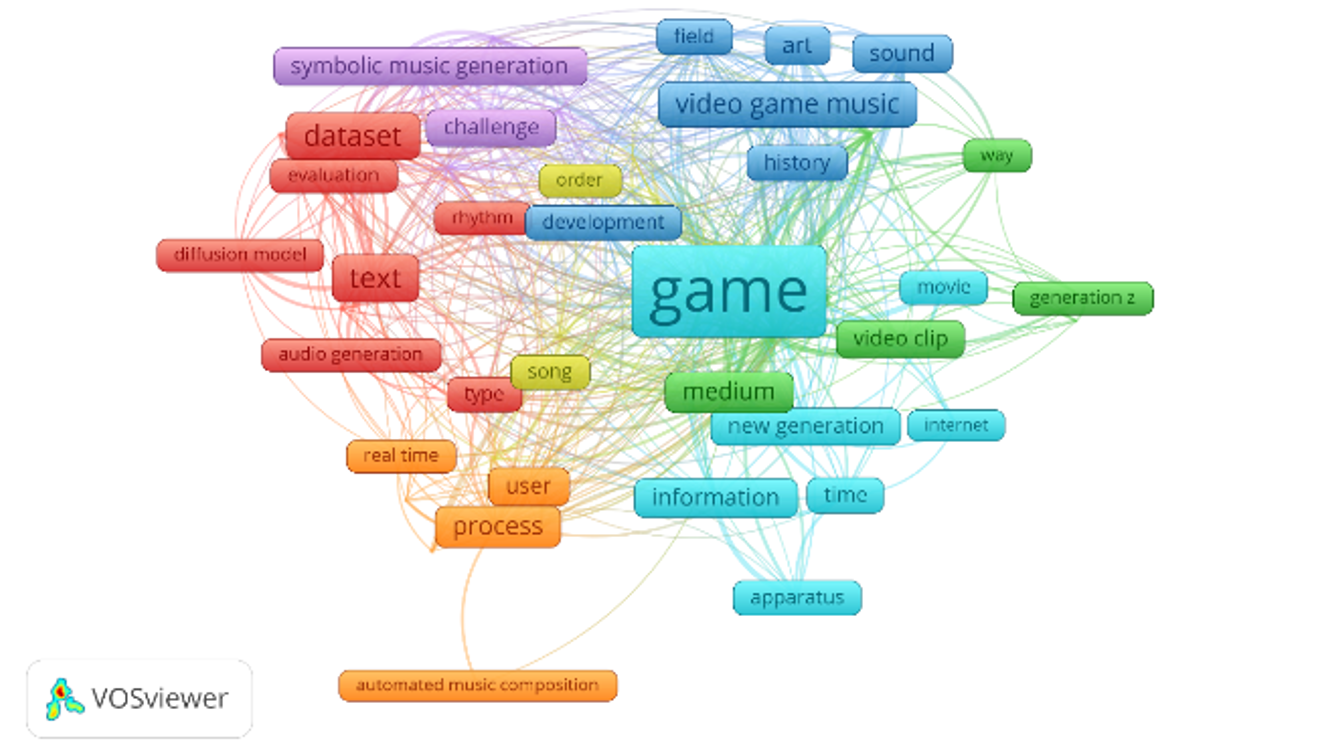
Penelitian ini bertujuan memetakan evolusi generasi musik berbasis AI, khususnya generasi musik dari video. Melalui analisis bibliometrik terhadap 999 publikasi ilmiah (1997-2025), kami menganalisis tren dan struktur konseptual menggunakan VOSviewer. Metode meliputi ekstraksi metadata, konstruksi jaringan ko-kepengarangan, dan identifikasi kluster dominan. Hasil mengungkapkan lima kluster tematik utama: model generatif berbasis teks, generasi musik simbolik, musik video game, integrasi multimedia, dan komposisi otomatis. Studi terbaru menunjukkan pergeseran ke arsitektur generatif multimodal, mengintegrasikan transformer dan model difusi untuk mengatasi tantangan penyelarasan semantik-temporal antara video dan musik. Penelitian mengidentifikasi kesenjangan utama: kelangkaan dataset berpasangan skala besar, kurangnya metrik evaluasi standar, dan terbatasnya sistem generasi real-time. Kebaruan penelitian ini adalah pemetaan bibliometrik pertama yang fokus eksklusif pada generasi musik dari video, memberikan fondasi bagi komunitas akademik dan industri untuk memahami lintasan dan arah masa depan bidang ini.
Keywords:
Artificial Intelligence, AI-Driven Music Generation, Bibliometric Analysis, Generative Models, Video to Music GenerationDownloads
References
Božić, M., & Horvat, M. (2024). A Survey of Deep Learning Audio Generation Methods. http://arxiv.org/abs/2406.00146
Briot, J.-P., Hadjeres, G., & Pachet, F.-D. (2019). Deep Learning Techniques for Music Generation - A Survey. http://arxiv.org/abs/1709.01620
Dannenberg, R. B., & Neuendorffer, T. (2003). Sound Synthesis from Real-Time Video Images.
DI, S., Jiang, Z., Liu, S., Wang, Z., Zhu, L., He, Z., Liu, H., & Yan, S. (2021). Video Background Music Generation with Controllable Music Transformer. MM 2021 - Proceedings of the 29th ACM International Conference on Multimedia, 2037–2045. https://doi.org/10.1145/3474085.3475195
Donthu, N., Kumar, S., Mukherjee, D., Pandey, N., & Lim, W. M. (2021). How to conduct a bibliometric analysis: An overview and guidelines. Journal of Business Research, 133, 285–296. https://doi.org/10.1016/j.jbusres.2021.04.070
Gan, C., Huang, D., Chen, P., Tenenbaum, J. B., & Torralba, A. (2020). Foley Music: Learning to Generate Music from Videos. http://arxiv.org/abs/2007.10984
Gu, X., Shen, Y., & Lv, C. (2023). A Dual-Path Cross-Modal Network for Video-Music Retrieval. Sensors, 23(2). https://doi.org/10.3390/s23020805
Ji, S., Wu, S., Wang, Z., Li, S., & Zhang, K. (2025). A Comprehensive Survey on Generative AI for Video-to-Music Generation.
Jiang, Y.-G., Wu, Z., Tang, J., Li, Z., Xue, X., & Chang, S.-F. (2017). Modeling Multimodal Clues in a Hybrid Deep Learning Framework for Video Classification. http://arxiv.org/abs/1706.04508
Kang, J., Poria, S., & Herremans, D. (2024). Video2Music: Suitable Music Generation from Videos using an Affective Multimodal Transformer model. https://doi.org/10.1016/j.eswa.2024.123640
Li, R., Zheng, S., Cheng, X., Zhang, Z., Ji, S., & Zhao, Z. (2024). MuVi: Video-to-Music Generation with Semantic Alignment and Rhythmic Synchronization. http://arxiv.org/abs/2410.12957
Li, S., Qin, Y., Zheng, M., Jin, X., & Liu, Y. (2024). Diff-BGM: A Diffusion Model for Video Background Music Generation. http://arxiv.org/abs/2405.11913
Li, S., Yang, B., Yin, C., Sun, C., Zhang, Y., Dong, W., & Li, C. (2024). VidMusician: Video-to-Music Generation with Semantic-Rhythmic Alignment via Hierarchical Visual Features. http://arxiv.org/abs/2412.06296
Lin, J.-C., Wei, W.-L., & Wang, H.-M. (2016). Automatic Music Video Generation Based on Emotion- Oriented Pseudo Song Prediction and Matching. MM 2016 - Proceedings of the 2016 ACM Multimedia Conference, 372–376. https://doi.org/10.1145/2964284.2967245
Lin, Y.-B., Tian, Y., Yang, L., Bertasius, G., & Wang, H. (2024). VMAS: Video-to-Music Generation via Semantic Alignment in Web Music Videos. http://arxiv.org/abs/2409.07450
Liu, X., Tu, T., Ma, Y., & Chua, T.-S. (2025). Extending Visual Dynamics for Video-to-Music Generation. IEEE International Conference on Program Comprehension, 2022-March, 36–47. https://doi.org/10.1145/nnnnnnn.nnnnnnn
Mao, Z., Zhao, M., Wu, Q., Zhong, Z., Liao, W.-H., Wakaki, H., & Mitsufuji, Y. (2025). Cross-Modal Learning for Music-to-Music-Video Description Generation. http://arxiv.org/abs/2503.11190
Mehri, S., Kumar, K., Gulrajani, I., Kumar, R., Jain, S., Sotelo, J., Courville, A., & Bengio, Y. (2017). SampleRNN: An Unconditional End-to-End Neural Audio Generation Model. http://arxiv.org/abs/1612.07837
Prétet, L. (2022). Metric learning for video to music recommendation. https://theses.hal.science/tel-03638477v1
Rai, A., & Sridhar, S. (2024). EgoSonics: Generating Synchronized Audio for Silent Egocentric Videos. http://arxiv.org/abs/2407.20592
Stewart, S., KV, G., Lu, L., & Fanelli, A. (2024). Semi-Supervised Contrastive Learning for Controllable Video-to-Music Retrieval. http://arxiv.org/abs/2412.05831
Su, K., Li, J. Y., Huang, Q., Kuzmin, D., Lee, J., Donahue, C., Fei, S., Jansen, A., Wang, Y., Verzetti, M., & Denk, T. (2024). V2Meow: Meowing to the Visual Beat via Video-to-Music Generation. www.aaai.org
Suríš, D., Vondrick, C., Russell, B., Research, A., & Salamon, J. (2022). It’s Time for Artistic Correspondence in Music and Video.
Tian, Z., Liu, Z., Yuan, R., Pan, J., Liu, Q., Tan, X., Chen, Q., Xue, W., & Guo, Y. (2024). VidMuse: A Simple Video-to-Music Generation Framework with Long-Short-Term Modeling. http://arxiv.org/abs/2406.04321
Wang, Z., Bao, C., Zhuo, L., Han, J., Yue, Y., Tang, Y., Huang, V. S.-J., & Liao, Y. (2025). Vision-to-Music Generation: A Survey. http://arxiv.org/abs/2503.21254
Yu, J., Wang, Y., Chen, X., Sun, X., & Qiao, Y. (2023). Long-Term Rhythmic Video Soundtracker. http://arxiv.org/abs/2305.01319
Zhang, L., & Fuentes, M. (2024). SONIQUE: Video Background Music Generation Using Unpaired Audio-Visual Data. http://arxiv.org/abs/2410.03879
Zhou, Y., Wang, Z., Fang, C., Bui, T., & Berg, T. L. (2018). Visual to Sound: Generating Natural Sound for Videos in the Wild. http://arxiv.org/abs/1712.01393
Zhuo, L., Wang, Z., Wang, B., Liao, Y., Bao, C., Peng, S., Han, S., Zhang, A., Fang, F., & Liu, S. (2023). Video Background Music Generation: Dataset, Method and Evaluation. http://arxiv.org/abs/2211.11248
Zuo, H., You, W., Wu, J., Ren, S., Chen, P., Zhou, M., Lu, Y., & Sun, L. (2025). GVMGen: A General Video-to-Music Generation Model with Hierarchical Attentions. http://arxiv.org/abs/2501.09972
Published
How to Cite
Issue
Section
License
Copyright (c) 2025 Ade Bastian, Ardi Mardiana, Muhammad Fahmi Ajiz, Satria Winata

This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.







